In a previous post (The Defect Dance) I mention the first point when finding a bug, "Can it be reproduced?". If the answer is no, I mention to make a note of it in case it happens again...
However, this is a bit of a simplification, there's a lot more to it than "Can a bug be reproduced?" Yes/No...
Bugs for whatever reason, can be intermittent/transient. Some bugs might only appear under very specific scenarios, under heavy load etc.
We've all been there as a QA professional, where we've experienced some quirky behaviour, that on first instance appears to be a bug, but you try and reproduce it, and you can't, and we all know that a developer will only be interested in a bug that is reproducible! So what's the next step?
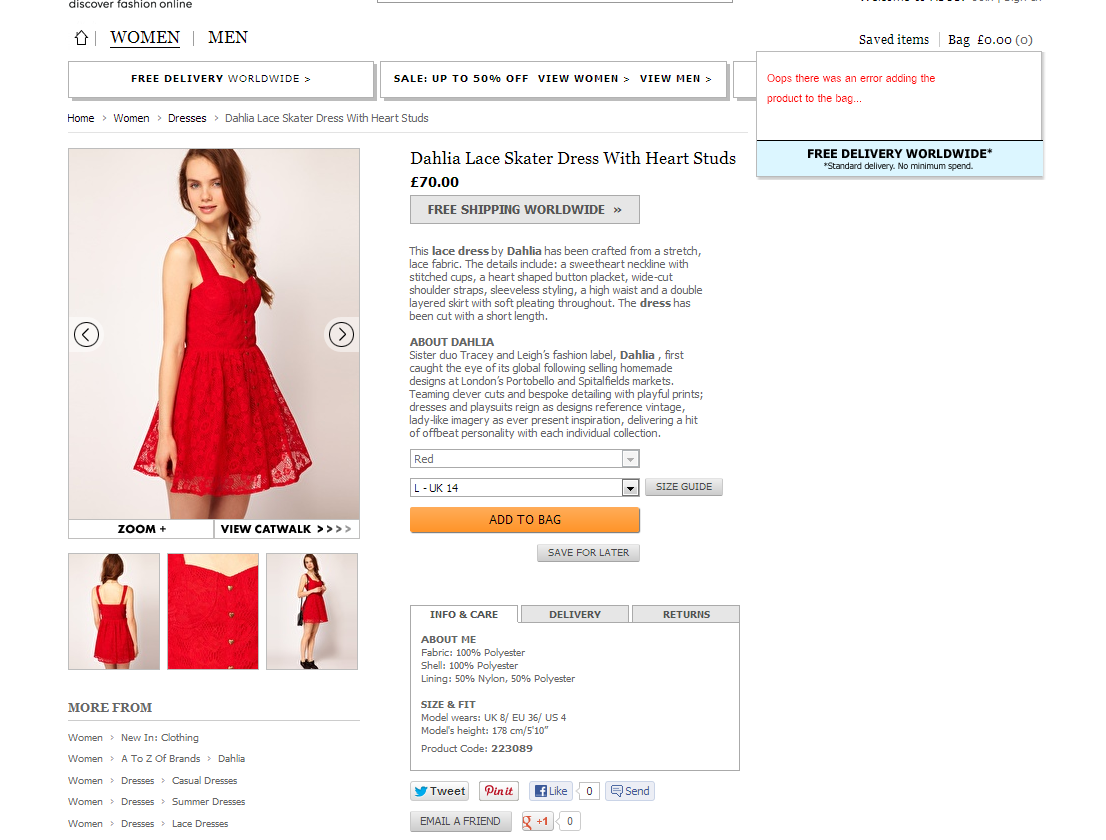
For the sake of this blog post we'll use an error on the asos website, for when you try to add an item to the bag...


One thing I find helpful is to look in the error logs, be that log4net or even the event viewer on the box that the service/app is hosted on, you can find information about the issue there (if you have logging set up of course :) ). From there you can often find information about what service it was that threw the error, and drill down a bit further. If you don't feel comfortable doing this, then you can speak to a developer and ask them to do this for you, but there's nothing, in my opinion to be scared about, viewing the logs should be a QAs bread and butter. There may or may not be something in the logs, depending if the error is server side or it may be client side. It is however a good starting point and can help you in your quest for discovering the issue.
If there is nothing in the error logs server side, then another possible cause may be a JavaScript error on the page itself, these can be viewed in the error console on the browser, in Chrome, this is easily accessed by hitting Ctrl, Shift and J (for other browsers view the page here). From here it will show any warnings or errors about any CSS, JavaScript there may be a JavaScript error in here that was preventing the add to basket from working (for instance was all the JavaScript loaded when the bug occurred).
Depending on the system architecture, there could be a caching issue, either in the browser or on the server, so it could be worth investigating that, closing the browser and clearing the cache (information around how to do this can be found here), see if the issue reappears.
If there is still nothing, then there may be a config issue on one of the boxes, it may be pointing to the wrong service that isn't accessible from your environment, so view the config around the services/app that are behaving erratically and you may find an issue there.
Failing all the above, it may be worth getting someone in who knows the system and talk them through what you were doing, they may spot something that you didn't, it might be that the service is slow to respond to the first call, and after that it's fine, so something like that points to a performance issue.
Also, you could try searching the bug database, there may be a similar issue logged already, which may have some more information on the circumstances that led to the bug, which could help in recreating it.
If all this fails, then I would let the team know, so that they too are aware that there was a problem, and if it arises again on any of their machines then they can let you know what it is that they were doing that caused it so you can perform the Defect Dance again.
How long should you spend investigating/trying to reproduce a bug?
The question that I do get asked, is how do you determine how long to spend trying to reproduce a bug, to which the obvious answer is the severity/priority of the bug, the more critical the bug would be, the longer you should spend looking for it. If it's a UI issue for instance, and you can't recreate it, then there's no need to investigate in such detail, but some research obviously would not go amiss.
.jpg)
So as you can see, it isn't as simple as is the bug reproducible? You can't give an immediate answer without investigating further, unfortunately, I couldn't fit all the above into the defect dance diagram, and thought it deserved a blog post in it's own right! Feel free to add any of your own comments on unreproducible bugs, or if you have your own stories....
However, this is a bit of a simplification, there's a lot more to it than "Can a bug be reproduced?" Yes/No...
Bugs for whatever reason, can be intermittent/transient. Some bugs might only appear under very specific scenarios, under heavy load etc.
We've all been there as a QA professional, where we've experienced some quirky behaviour, that on first instance appears to be a bug, but you try and reproduce it, and you can't, and we all know that a developer will only be interested in a bug that is reproducible! So what's the next step?
For the sake of this blog post we'll use an error on the asos website, for when you try to add an item to the bag...
{kind=link}

So, don't immediately try and recreate the issue, I once read an interesting analogy about a mongoose and an antelope, and how they react to certain situations. You want to try not to be a mongoose, as their initial reaction is to attack blindly and often irrationally when it is backed into a wall, and staring death in the eye, what you want to do is be an antelope, who will freeze and think about the next move....
In this instance, make a note of the browser, the browser version, the url, the product id...
So after thinking about it, you want to try and replicate the problem, you perform the same steps...

Lo and behold! It works!!! Do not accept this as "there was never a bug"....
This could be for any number of reasons. The first thing to do is make a note of what it is that you did differently the second time as opposed to the first (this is why it's important to make a note of any information you have when the bug first appears). There may be an obvious difference, so we look at the differences and notice that it's the product that is causing the issue, this means that it's likely a data issue with that product, so we can drill down and investigate why. However, pretend, for this blog that there are no apparent differences, what do you, as a QA, do next?
Again, we take the mindset of an Antelope... And think about the next move.
If there is nothing in the error logs server side, then another possible cause may be a JavaScript error on the page itself, these can be viewed in the error console on the browser, in Chrome, this is easily accessed by hitting Ctrl, Shift and J (for other browsers view the page here). From here it will show any warnings or errors about any CSS, JavaScript there may be a JavaScript error in here that was preventing the add to basket from working (for instance was all the JavaScript loaded when the bug occurred).
Depending on the system architecture, there could be a caching issue, either in the browser or on the server, so it could be worth investigating that, closing the browser and clearing the cache (information around how to do this can be found here), see if the issue reappears.
If there is still nothing, then there may be a config issue on one of the boxes, it may be pointing to the wrong service that isn't accessible from your environment, so view the config around the services/app that are behaving erratically and you may find an issue there.
Failing all the above, it may be worth getting someone in who knows the system and talk them through what you were doing, they may spot something that you didn't, it might be that the service is slow to respond to the first call, and after that it's fine, so something like that points to a performance issue.
Also, you could try searching the bug database, there may be a similar issue logged already, which may have some more information on the circumstances that led to the bug, which could help in recreating it.
If all this fails, then I would let the team know, so that they too are aware that there was a problem, and if it arises again on any of their machines then they can let you know what it is that they were doing that caused it so you can perform the Defect Dance again.
How long should you spend investigating/trying to reproduce a bug?
The question that I do get asked, is how do you determine how long to spend trying to reproduce a bug, to which the obvious answer is the severity/priority of the bug, the more critical the bug would be, the longer you should spend looking for it. If it's a UI issue for instance, and you can't recreate it, then there's no need to investigate in such detail, but some research obviously would not go amiss.
.jpg)
So as you can see, it isn't as simple as is the bug reproducible? You can't give an immediate answer without investigating further, unfortunately, I couldn't fit all the above into the defect dance diagram, and thought it deserved a blog post in it's own right! Feel free to add any of your own comments on unreproducible bugs, or if you have your own stories....
I had a similar experience with a issue, this was related to user permissions. There was a particular issue with functionality not loading when you are a lower privileged user, but works completely fine when you have higher permission settings like administrator.
ReplyDeleteI remember logging this issue and reopening this for more than 3 times, because we initially thought this is a data issue before both the dev and I could realize this is related to permission setting!
Glad it was all sorted at least. It can be most frustrating sometimes!!
DeleteIt was working perfectly fine with me too, hope it will work for you too and you can have what you want. Goodluck man and best wishes
ReplyDeleteVery good informative article. Thanks for sharing such nice article, keep on up dating such good articles.
ReplyDeleteBest Digital Transformation Services | DM Services | Austere Technologies